
Best Music Best You
Diya Peng(dp624) and Shenghua Li(3293)
Project Demo
Objective
Our goal is to build the raspberry pi with a camera to recognize the face before the camera, and then raspberry pi will query the database inside to find the favourite music style of these people, then the RPi will use the existing music of this style to generate a new music by deep learning.
Introduction
- The intuition of this project comes from a desire to take advantage of deep learning more efficiently and innovatively instead of only doing some classification tasks. This idea is motivated by combining two famous deep learning applications on our platform: using face recognition to identify different people and according to the data related to their favorite styles of music, we then use another interesting idea of “generating music of the same style” (one example is like the “deep-jazz” on the GitHub). The main aspect is to take the camera and use the face-recognition algorithm to identify different people, then use the data stored in the raspberry pi, we can play self-generated music of certain styles (classic, jazz, popular and so on) for different people.Our project contains the following parts:
- Building the raspberry pi with a camera to recognize the face before the camera
- Using face recognition to identify different people
- Using Natural Language Proessing to generate unique music for each person
- Playing the music belonging to the person after recognize the face
Design
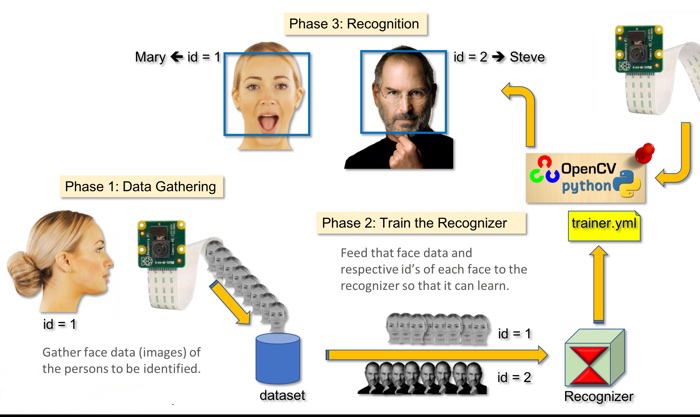
design steps of face recognition
- Using OpenCV to achieve face recognition and raspberry pi works as the operating system, it involves four steps:
- Install camera with raspberry pi
- Face detection and dataset collection
- Training recognizer
- Face recognition
Design steps of music generation
- Using TensorFlow to train and test a NLP (natural language processing) to generate music of the same style. It includes following steps:
- Collect and preprocess basic music data
- Use Google Colab to train a NLP probability model based on LSTM
- For one model, it can generate a new music of the same style
- Train and generate new music by training new data

Design steps of playing music with specific face
When people stand in front of the camera of the raspberry pi, if this people’s face is on the collected dataset, this people’s face will be recognized and played the specific music, it achieves multiple users with multiple music.

Issus & Resolve
Testing
We tested three parts of our project, face recognition, music generation and combination of face recognition and music generation
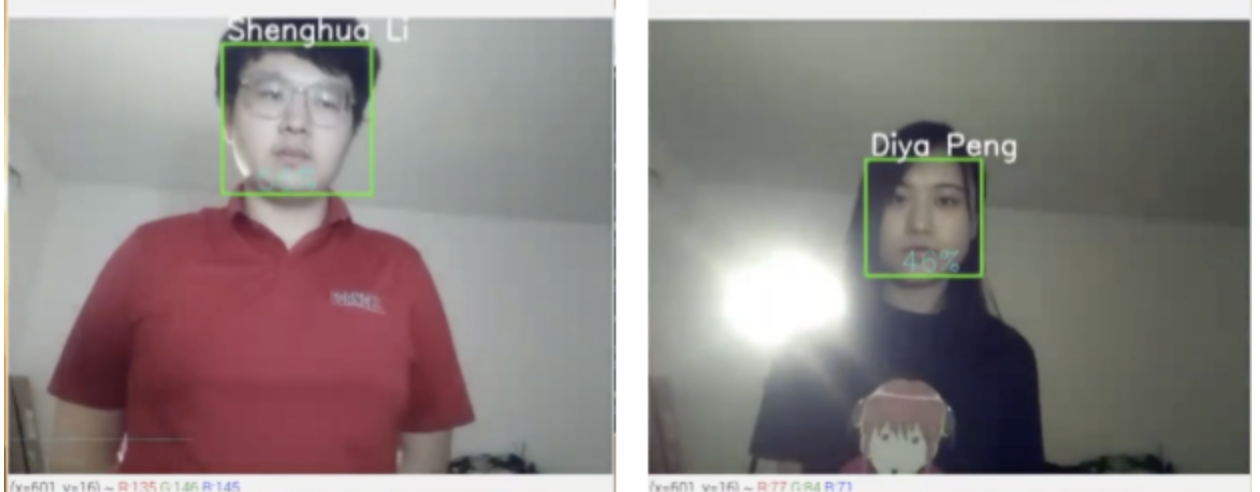
Face recognition
The figure below shows the test result of face recognition, we can see it recognized Shenghua Li’s face with 55% confidence and Diya Peng’s face with 46% confidence.
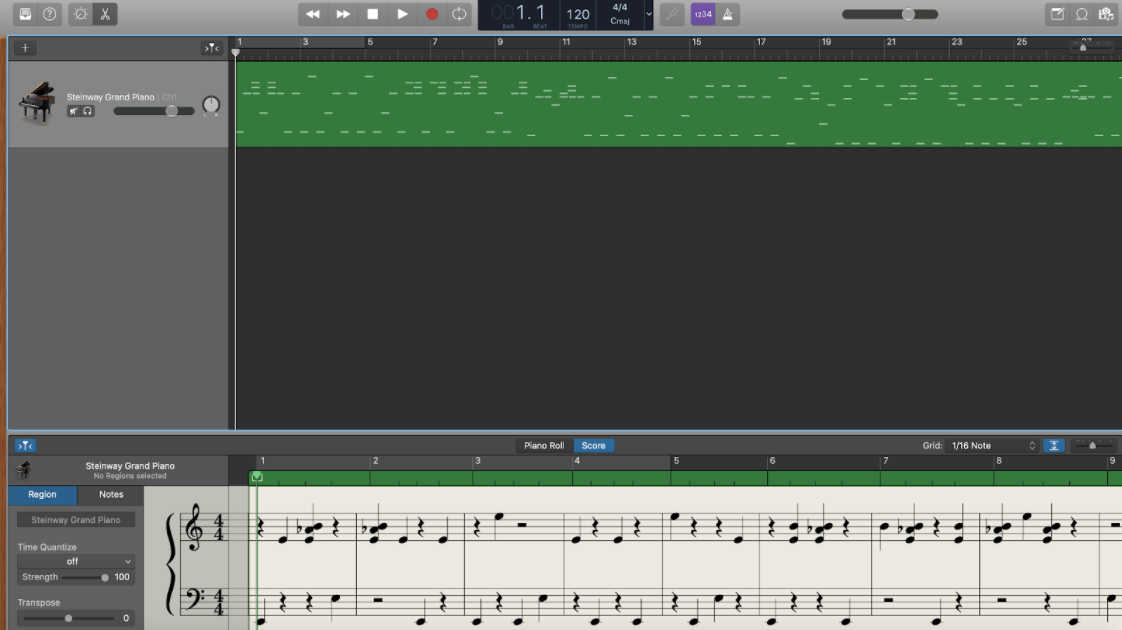
Music Generation
The figure below shows the result of a generated music by learning from Schubert's piano music. As we can find in the figure, the chords generated are good and also sound nice.
Combination of face recognition and music generation
The figure below shows the test result of our project, the RPi could capture the face and then make judgment which music (generated by NLP by some music of the same style) to play.

Results & Conclusion
Our project reached our expectation.
Face recognition
The camera can successfully detect multiple people’s face and recognition their face.
Music generation
The NLP model can successfully train the model and generate new pieces of soundful music.
Combination of face recognition and music generation
When people come to the camera of the Raspberry Pi, the speaker would play the unique music generate for that person, our project can be appled for multiply users.
Future Work
We will enable pyGame screen on our project, so when people come to the camera of the Raspberry Pi, he can see his photo taken by the camera on the screen and the displayed music name would also be shown on the screen.
Budget
| Vendor | Description | Quantity | Unit Cost($) | Total Cost($) |
|---|---|---|---|---|
| ECE Department | Raspberry Pi 3B | 1 | 35.00 | 35.00 |
| ECE Department | Raspberry Pi camera modele V2 | 1 | 25.00 | 25.00 |
| ECE Department | JBL Speaker | 1 | 25.00 | 25.00 |
| Total | 85 | |||
References
Work Distribution
For our ‘best music best you’ project, diya implemented the face recognition part, shenghua implemented the music generation part, and we did the combination section together.